Robots Need More Than VLAs & World Models
Everybody is racing to build larger VLAs, bigger robot policies, and more powerful world models. That is the wrong race.
Robotics does not need another demo model. It needs a complete, coherent system: one that can turn physical experience into robot-usable supervision, adapt across embodiments, recover when reality changes, and complete useful work in the real world. Building it requires new model architectures aimed at the whole problem, not more policies aimed at one slice of it.
Today we are releasing our position paper. It diagnoses the real bottleneck in robotics and sets out what the field needs next.
The world is full of physical experience. Robots can't use most of it.
Robotics is entering its foundation-model moment. The field has larger policies, broader robot datasets, better simulation, stronger world models, and the first serious attempts at generalist control. That progress is real.
But robotics still doesn't have what language had. Language models scaled because text was already digital, abundant, and structured by human use, and the internet handed them a vast substrate of learnable supervision. The physical world offers no such gift. Human motion doesn't arrive with robot actions, internet video carries no force or torque traces, and a factory workflow isn't labelled with task phases, contacts, rewards, or failure modes. A correction made by a person doesn't tell a different robot body what to do.
The world contains the evidence. Robots lack the grounding. That is the bottleneck.

VLAs are not enough
Vision-language-action models are one of the most important advances in robotics. They bring perception, language, and action into a shared policy and let a robot condition behaviour on instructions, observations, and demonstrations.
But a VLA is still mostly answering one question: what action should the robot take next? Real work asks more. What is the task trying to achieve? What must be true before acting? Where should contact happen, and what force is safe? What changed, and what went wrong? What should carry across to a different robot, tool, or site?
A plausible next action is not a finished job.
World models are not enough
World models matter too. A robot has to predict consequences, imagine futures, and reason about dynamics before it acts. But prediction is not competence. A world model can say what might happen next, a planner can search for a path, a simulator can generate rollouts. None of that, on its own, tells a robot what makes work succeed.
Real work turns on small, unforgiving moments. A cable sits near the clip but isn't seated. A part moves but isn't assembled. A drawer slides but doesn't close. In robotics, "close" is failure. Understanding the scene is not completing the task.

The missing ingredient is grounding
Grounding is the work of turning raw physical experience into something a robot can learn from: actions, contacts, goals, rewards, the structure underneath a task. Today's strongest robot systems still lean on robot-native supervision instead: observations paired with actions, task labels, and rewards already expressed in a robot's own coordinate system. That works, but it doesn't scale like the internet. Every trajectory is tied to a body, every action to a control interface, every task to a setup, and every failure is expensive.
Meanwhile the world holds far more physical experience than any robot fleet could ever collect directly. So the question is no longer only how to gather more robot demonstrations. It is how to convert the experience that already exists into supervision a robot can use. Robotics has to move from a robot-data-centric pipeline to a grounding-centric one.
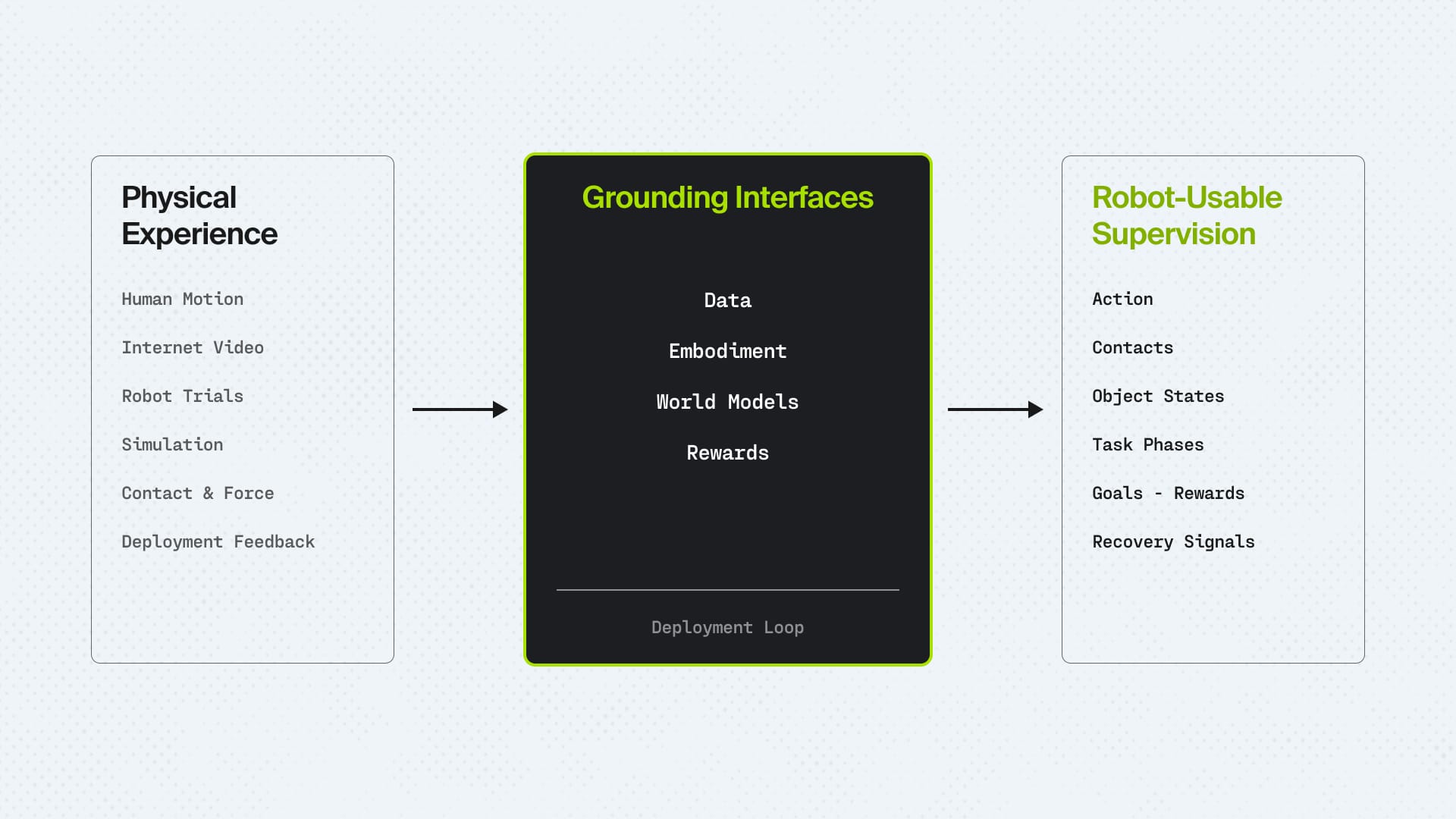
The four interfaces robotics needs
Concretely, the next robotics architecture needs four grounding interfaces, each still absent or underbuilt today.
Extraction. A video of someone doing physical work holds far more than pixels: task intent, contact, object-state changes, progress, failure, correction, success. Until those signals are extracted and grounded, it stays weak supervision. An extraction interface turns unstructured behaviour into task phases, object states, contact events, goals, rewards, and recovery.
Embodiment. A human action is not a robot action. A hand, a two-finger gripper, a suction tool, a humanoid arm, and a mobile manipulator don't share morphology, constraints, or affordances. An embodiment interface decides what transfers, what changes, and what a given body simply cannot execute.
Counterfactual grounding. A world model on its own is exactly what we just called insufficient: it predicts plausible frames without knowing what makes work succeed. The fix isn't to discard prediction but to ground it. Counterfactual grounding forces prediction to answer not just what comes next, but what would happen under a different action, and to preserve the variables control depends on: geometry, object state, contact, force, constraints, and physical consequence. One predicts what the world will look like. The other, what it takes to act in it.
Execution feedback. A robot needs to know whether the work is progressing, not whether a frame looks plausible. An execution interface grounds progress, success, and failure from video, language, state change, and deployment outcomes, turning physical evidence into learning signal.
Closed by a deployment loop, these four are the system robotics is missing. Not four models wired together, but one system that has to do all of it at once, not a bigger policy and not a smarter integration of what already exists.
Beyond the demo
The field is full of impressive demos. But a demo is a single clean clip, captured once under conditions the team controls. Deployment is everything it leaves out: the site the lab never saw, the friction that's different, the object that jams, the operator who interrupts, the job that still has to finish.
The frontier isn't the clip. It's the loop: the work that only starts after the camera stops, where every attempt, correction, and failure becomes what the next robot begins from.

The case for a new architecture
Robots Need More Than VLAs & World Models is a position paper about the system-level bottleneck in robotics. VLAs matter, world models matter, simulators and reward models and robot datasets matter. None of them is sufficient alone, and stitching them together is not the answer either. What the field needs is a new robotics architecture, one that grounds physical data, transfers across bodies, predicts consequence, judges progress, runs in real time, and learns from active deployment.
This is where Motoniq starts. Not another demo model, not another integration layer, but a new architecture for machines that do useful work in the real world.
Less hype. More work.
Authored by a leading consortium of scientists, engineers, builders, and operators across AI, robotics, control, and real-world deployment, including Haitham Bou-Ammar, Mac Schwager, Jan Peters, Marco Hutter, César Cadena, and Arash Ajoudani. Stanford · TU Darmstadt · ETH Zurich · UCL · IIT